I can get answers about how to do something with a piece of software or other tech quicker with the AI Overview after googling than I can by sifting through documentation. Is AI coming for documentation and the jobs of docs writers? No. Because AI needs to be trained on the documentation that humans write in order to provide speedy reference answers.
Blog
-
Game of the day (gotd) #1
How did I defeat myself vs. Stockfish engine today?
By blocking pieces from developing. This is kind of a bad habit with me, and it’s usually how my game starts to fall apart. For example, my move 2) … Bd6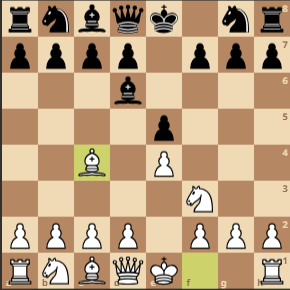
-
“Case notes” for library software
A bug ticket for an open source library software feature request made me think of a “cultural” difference between the workflows for public-facing library employees and customer support representatives. I have had experience with both workflows. One big difference on the surface is in the jargon, patrons (the users of a public library) vs. customers.
There’s really no formal ticket system when helping patrons. Opening a “ticket” of sorts for every patron would be overkill, but the de facto standard of library transactions, where there is in all but the most complicated or escalated issues a complete lack of any sort of log after helping a patron, is not very helpful either.
In my experience there have been times where you wish you could talk to the coworker who last helped the patron, because the patron is back and things are not resolved, but neither you nor the patron can identify who helped them. I can also recall times working with CSR software at call centers, where you were given a short set amount of time to write case notes summarizing the support given before the next call in queue was put through. So every transaction was automatically logged and traceable to the CSR who handled it.
Use of ILS patron notes feature on every transaction is the closest approximation to a CSR case notes workflow, but patron notes wasn’t meant to log a patron’s entire transaction history, all of which would have to be stored in server databases, and it isn’t customary for library workers to take notes after every patron.
tldr;
Could an ILS be set up to generate locally-stored logs for every transaction? Pass the storage burden to all the local workstations that outnumber the servers.
Implement logs by an additional action for every transaction-finishing button in the UI. The action would be to newline append staff member name, patron barcode, and a timestamp to a local log file. For privacy no book titles/barcodes go into the logs.
There would have to be some kind of workstation counter state, after x number of appends to a text file, make a new one, so that you don’t have experience latency running the native text editor due to MB-size text files. So you imagine a log folder full of text files for even a month. On windows at least, the individual content of all text files in the pwd can be searched using the windows explorer ui.Let me not go down the rabbit hole about the details of local storage for log files.
Imagine a patron is back with an unresolved issue but neither staff nor the patron can identify who last helped the patron.
To better log for follow up with the previous staff member, log out and log back in to the web staff client every time the next staff member goes on duty, and they should log in with either a user name or workstation name that identifies the staff member.
But in my experience, everyone logs in with the same username, the one for the library department, and everyone’s in a habit of
- leaving the workstation name as the same arbitrary codename from first use and
- leaving workstations logged into the same session from the time we open until the time we close, unless the browser is closed inadvertently.
Given these usage habits, I would suggest the following:
- add a 4th input for the staff member’s name to the staff login sign in form, and
- that the username @ workstation ID + Staff Name be enlarged in font and moved from the navbar corner to the center of the home splash with the Evergreen logo
Seeing someone else’s name in big print will encourage the next staff member at the workstation to update.
Instead of printing the staff name on the home splash, duplicate an
<input>pre-filled from whatever was submitted on the login, and the staff name can be easily edited, as well as recognized as editable, when the next staff member comes to the workstation.Every transaction-finishing button can append info from the sign in form to the log, whether that log goes into the database or local storage as a text file log.
-
Search and discovery in online library catalogs
So today I’m facing the difficulty of finding books with age hold protection in the Concerto database. My first guess is to search for Concerto’s new books. I do this through advanced search and tick off new arrivals, but no results. I go to my local library’s implementation of the Evergreen-ILS OPAC and try the same advanced search for its new books, and, latency. Spinning its wheels far longer than my short attention span can tolerate.
I still “dream” about a book object with properties that facilitate “orgunitsettings” like if the book had a property that it’s age protected, then you have a rule that excludes any book with that property from any available holds calcs. Well how do i know that’s not how it’s already coded in Koha or Evergreen. AND then there’s the problem of storing all those objects. Yeah, what you would actually store is a database full of property values and then construct a book object from a set of them. Googled Java object database.
It used to be that you wanted an ILS with the discovery power of Amazon. I felt the need for that again today when it seemed like an act of congress to just get some paginated search results for all the new books in one system from Evergreen, and I found myself using an old trick of the trade from library days, going to Amazon to discover what the bestselling new books actually are right now, so I can search a specific title in Evergreen and not tax its search power.
But it’s 2024 now. Maybe you should look beyond Amazon/Google type searching and see how LLMs could be your discovery and reader assistance… Yikes sounds like AI is coming for a librarian’s job.
-
Autoconf in WSL2 with MinGW
When you install an Ubuntu distro with WSL2 on Windows 11, Ubuntu can see your Windows files through the Linux path
/mnt/c. WSL2 Ubuntu also utilizes Linux packages and applications in your existing Windows installations of MinGW, usually through the path/mnt/c/MinGW. MinGW comes with Git For Windows
installation, for example. I had uninstalled my WSL2 Ubuntu Bionic Beaver and gone without WSL2 for a long time, trying out full Ubuntu installations on old laptops.Now I’m giving WSL2 another try with Ubuntu Jammy, since over time I haven’t accumulated that many repos on Ubuntu, they’re all on Windows.
Working on installing a server from a repo I have on Windows, I had to run autoreconf as a preliminary, which immediately failed with the error:
Can't locate Autom4te/ChannelDefs.pm in @INC (you may need to install the Autom4te::ChannelDefs module) (@INC contains: /mingw/share/autoconf /etc/perl /usr/local/lib/x86_64-linux-gnu/perl/5.34.0 /usr/local/share/perl/5.34.0 /usr/lib/x86_64-linux-gnu/perl5/5.34 /usr/share/perl5 /usr/lib/x86_64-linux-gnu/perl-base /usr/lib/x86_64-linux-gnu/perl/5.34 /usr/share/perl/5.34 /usr/local/lib/site_perl) at /mnt/c/MinGW/bin/autoreconf-2.68 line 40. BEGIN failed--compilation aborted at /mnt/c/MinGW/bin/autoreconf-2.68 line 40.What happens is that the autoreconf-2.68 Perl script in your C:\MinGW\bin looks for the value for key “autom4te_perllibdir” in your perl environment and fails if that key-value pair hasn’t been written. It just means the paths aren’t set up, not necessarily that you don’t have the Autom4te package. You’ll probably find do have Autom4te installed in your MinGW if you poke around in
MinGW\share\autoconf. Anyway, I went to MetaCPAN to find some docs on@INC. I applied what I found in the documentation as best as I could by running some Perl commands in the WSL2 terminal, but I can see that the commands didn’t cause any changes that stick. The error persists.I’m going to keep trying to change the Perl environment. The %ENV variable Perldoc displays an example script that shows how to set key-value pairs. Also, the autoreconf-2.68 script’s 3rd line gives an example of how to reference the value for key “autom4te_perllibdir”. Enter a perl statement to set a value for “autom4te_perllibdir” on the command line as follows.
$ perl -e 'my $dir = "/mnt/c/MinGW/share/autoconf/Autom4te/"; $ENV{"autom4te_perllibdir"} = \$dir'That didn’t work!Well honestly I would want WSL2 to have installations in its Linux root rather than use MinGW. So how about this, if you find your Linux package on WSL is sourced from a MinGW installation, just “reinstall” the package with apt.
-
Object references in Python
In Python you can’t modify a global variable within a function, but you can call object methods that mutate a global object in a function, I think, and I also wanted to confirm that it is a reference to an object that is stored in a collection when you append an object to the collection, just like with arrays. So I fired up the Python REPL…
from collections import deque class Thang: def __init__(self): self.about = 'yo listo = deque() def fillr(): th = Thang() listo.append(th) return fillr() listo deque([<__main__.Thang object at 0x000001DA8A8A9D30>]) listo[0].about 'yo' -
JS journey retrospect
Last year I “wondered if MVC was even the best design for a chess game,” but if I had taken the time to read about the Universal Chess Interface (UCI) I would have seen that MVC is a common design for online chess. If I had built to UCI specs and selected a full-stack framework instead of trying to write backend from the ground up in Node, I might not have given up and resorted to just writing frontend for a platform service.
Sure, online chess is a solved problem, but I was reinventing the wheel for learning’s sake.
-
React Chess app
This single-page app chess game is live on Netlify. It’s logo is an image of IC 434, the Horsehead Nebula, that I took using iTelescope.net.
Building this app with a Next.js template was an opportunity for me to learn to write pure functions. It was a major milestone in my learning journey, as someone who has been dependent on the use of
forloops and array mutations since college! It’s amazing to see how much you can get done with onlyconstand once I got used toArray.prototype‘smapandfilterI think I actually prefer them toforloops. Last but definitely not least with pure functions,
was learning to write recursion. Taking out pencil and paper and planning out the function composition necessary to get me from point A to point B was what enabled me to finally write a working recursive function. -
JavaScript journey
Making a chess game has been the pet project nearest and dearest to my heart. Through making a chess game, I built up my HTML, CSS, and JavaScript skills, tried out several styling aids such as Bootstrap, Sass, and Bulma, learned about MVC architecture, and did a deep dive into writing elegant/efficient solutions in the problem domain. MDN Web Docs were my JavaScript and Web API reference of choice, and I was appreciative of hints into the problem domain offered by sites like Chess Programming Wiki without giving away specific “code spoilers,” speaking of which, I know there are existing, proven solutions out there for chess engines and frontends: Stockfish, GNU Chess, Lichess, etc., and reinventing the wheel was just my way of teaching myself to code with something that interested me.
I first attempted MVC with the UI and the data-generating backend modules both coded in vanilla JS, with a NodeJS simple server. It was a challenge to avoid antipatterns and ensure SoC without writing within a framework, and sometimes I wondered if MVC was even the best design for a chess game, so I was pleased to
finally refactor the code into the React framework, creating a working UI in much less time than it took for me to code vanilla MVC View objects!